The Advanced Query Screen - A Deep Dive
The Advanced Query Screen - A Deep Dive somebodyThe Query Screen
A Deep Dive
Artificial Intelligence
First, understand that the entities we refer to as "Artificial Intelligence" are technically referred to as Large Language Models (LLMs). They are these massive computers that have been trained on massive amounts of data to do one thing extremely well: anticipate the next word.
"A large language model or LLM is a type of artificial intelligence system that is trained on massive amounts of text data. This allows the system to generate coherent and human-like text by predicting the next word or sequence of words based on the previous text. Unlike traditional AI, LLMs don't rely on rules programmed by engineers. Instead, they learn patterns and associations directly from the data."
These LLMs are also stochastic, meaning they don't have a true semantic understanding of concepts or a persistent memory of facts. Each response is generated afresh based on statistical patterns learned from data, not a knowledge base of facts.
In other words, they only know what you tell them at the time you tell it to them and can't remember what you told them unless you remind them of it.
Hence, the query process we have designed to take advantage of their amazing ability to sample probable next words/text and leverage knowledge acquired from pre-training data, as well as analyze and summarize text presented to them.
Note:
This is how the AI itself responded to my statements above.
"But it's not quite right to say we "don't know anything" beyond the current context. The pre-training gives us substantial linguistic knowledge and common sense patterns that inform our responses. We leverage this background knowledge, along with the current context, to generate each reply.
We don't have true semantic understanding of language or maintain long-term factual memories. Our knowledge comes from statistical patterns, not a knowledge base. And our responses are transient, generated afresh each time based on the prompt."
LOL.
The Query Process
So, now that you understand a bit about our query screen and how AI works (straight out of the AI's mouth), let's talk about the Query Process. This is a very simple flowchart of our current process:
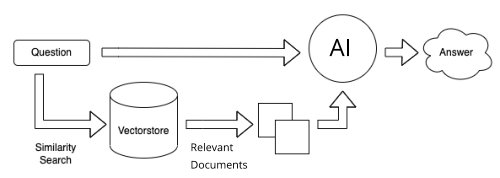
- Enter your question.
- The question is vectorized and sent to the vector store. The vector store is where all the vectorized Real Estate Books AI publications are stored.
- A search of the vector store is executed.
- A cosine similarity search is performed with your vectorized question against the stored Real Estate publication vectors.
- Documents with the closest similarity (the most "relevant" documents) are returned. We refer to these as our "context documents".
- Relevant context documents along with Question are sent to the AI.
- The AI examines this information and -- hopefully -- returns a useful answser.
This is a very simple explanation of the process. There are other steps that can and do occur in our system, but if you understand the above, then you have a basic grasp of the Embedded Document Chat Completion Process which is the core of virtually all "Chat with your PDF" types of services that are currently offered as a result of the recent AI explosion.
Using Our Query Screen
So, how do we use this query screen, considering the process, to get the best answers possible from the California Real Estate publications we have stored?
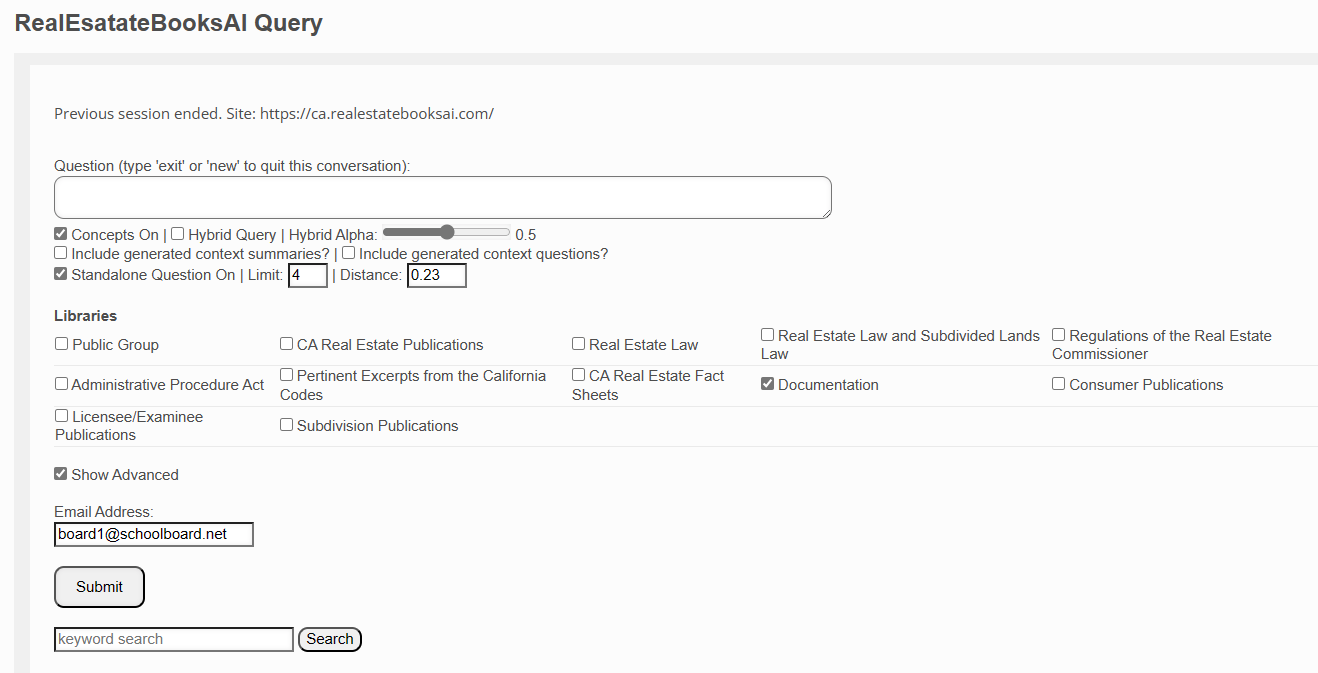
- Question
-
Let's chat! Ask your real estate question naturally, as if speaking with an agent. Instead of saying "ca disclosure laws", you could ask "What are the rules around disclosures when selling a home in California?"
-
Tips:
- Use full sentences and conversational style
- Give context if needed, like "We're selling our California home. What disclosures do we need to provide?"
- No keywords required
- The AI will understand and give the most relevant real estate law answer it can
-
This system maintains our conversation history. So each question builds on the last.
-
To start a new topic, type "new" or "exit".
-
You can hit Enter to submit, or click Submit button.
-
- Concepts On
- This option tells the system to extract the core concept(s) from your question before retrieving context.
- It makes an API call to the AI to analyze your question text. The AI identifies the central topic or subject.
- For example, from the question "What are the rules for disclosures when selling a home in California?" it would extract "California home disclosures" as the key concept.
- This concept is then used to query the knowledge base and retrieve the most relevant context documents about that specific topic.
- The context documents are critical because the AI uses them, together with your question, to generate the answer.
- Getting context documents closely related to the core of your question results in more pertinent, useful responses.
- In contrast, without this analysis, the context documents may be too generic and wide-ranging.
- In summary, the Concepts On option focuses your question to retrieve targeted context and improve the answers provided by the AI.
- Pro tip: Keep an eye on the "concept" returned by your query screen and the relevant documents. If the concept submitted is not bringing back the documents you expect, you may want to untick this option, which will have the submitting the exact text of your question as the vector store concept on the next submission.

- Hybrid Query | Hybrid Alpha
- This feature controls how the vector store interprets your question's core concept when retrieving context documents.
- It uses a scale from 0 to 1 called Hybrid Alpha. This determines if it performs a keyword-based or semantic-based search.
- A value closer to 0 means the vector store does a more keyword-focused search. It emphasizes matching your exact words and phrases.
- A value closer to 1 means a more concept-focused search. It looks for documents related to the broader meaning and ideas.
- For example, with a question about "California home disclosures", a keyword search would look for documents containing those exact words.
- Whereas a semantic search would find documents about the general topic of real estate disclosures in California, even without that specific wording.
- Adjust the Hybrid Alpha slider based on whether you want results matching the precise terminology or the general concepts from your question.
- In summary, the Hybrid Query option allows you to control how literal or conceptual the search is for context documents related to your question's core concepts.
- In this example, the correct multiple choice question was "Rumford Act". However, this term was not mentioned in any of the DRE publications available in the REBAI library. So, this was the initial response:

- However, when documentation on the Rumford Act was added, we used the Hybrid Alpha option to assure that the search leaned more heavily on keywords:
- And this was the subsequent answer:

- Include generated context summaries?
- Due to length limits, some documents are divided into smaller "chunks" when indexed.
- To maintain the overall context, each chunk has the summary of the full source document attached.
- These summaries act like descriptive labels, capturing the main concepts of the whole document.
- This option allows including those summaries when searching for relevant chunks.
- The search looks at both the chunks and their attached summaries.
- It retrieves chunks where the source document summary is related to your question.
- It helps find all relevant chunks that share concepts.
- Without the summaries, the chunks lose their broader contextual connections.
- The downside is more processing time if there are many summaries.
- In summary, this option utilizes the summaries to find relevant chunks based on the source documents' core concepts.
- Include generated context questions?
- Each document has automatically generated questions attached to it when indexed.
- These questions provide additional context about what each document contains.
- If this option is enabled, the search considers both the documents and the attached questions.
- It retrieves documents where the document content AND the generated questions are relevant to your original question.
- The questions provide additional signals to find documents that are contextual matches beyond just the document text alone.
- An attached generated question may be similar to your actual question.
- If disabled, only the document content is matched, without using the questions.
- In summary, this option allows the search to leverage the extra context from the generated questions attached to each document to improve matching.
- Standalone Question On
- This option creates a summarized, standalone question based on the chat history.
- Rather than sending the full conversation, it forms one comprehensive question encapsulating the key concepts.
- This standalone question is sent along with the actual latest question to the AI.
- It provides a condensed version of the context, giving the essence of what the chat has been about.
- For example, if you first ask "What are the disclosure laws when selling a home in California?" and then ask "Are there any exceptions to those laws?", the AI needs the context to understand the meaning of "those laws".
- Without the standalone question providing the necessary context, the AI would not know what "those laws" refers to in the follow-up question.
- By condensing the chat history into one summarized standalone question, the AI has what it needs to make sense of references back to previous parts of the conversation.
- This enables it to give much more coherent and useful responses.
- Pro tip: Because this option changes the the text of the actual question entered, it could prove problematic if the AI is struggling to or unable to answer a question adequately. Sometimes, you may want to pass exact text of the question as you entered it to the AI. In that case, you would untick this option.
- Limit
- By default, the system returns 5 context documents to the AI, even if fewer are needed to answer the question.
- For example, if the first document contains the full answer, the other 4 documents are still returned.
- This uses more tokens, since the AI processes unnecessary documents.
- It also reduces the number of queries you can make given the token limits.
- This option allows setting a lower limit, like 1 or 2 documents.
- This sends only the minimum needed context to the AI.
- It saves tokens since extra documents are not processed once the answer is found.
- The downside is it risks missing helpful supplementary information.
- But for many questions, 1 or 2 documents are sufficient context.
- In summary, reducing the limit cuts costs and lets you stay under token usage quotas, at the expense of potentially useful additional context.
- Distance
- The system matches your question to relevant documents using something called "cosine similarity".
- This gives each document a score for how closely it matches your question.

- It's like comparing two documents and rating their similarity.
- The more related a document is to your question, the higher its similarity score.
- Or to put it another way, the more related a document is, the lower its "distance" from your question.
- This option sets a limit on the maximum distance allowed for documents.
- Any documents with distance scores above the limit are filtered out and not returned.
- So a lower limit means only documents very closely related to your question are included.
- A higher limit includes documents that are more loosely related.
- The right setting depends on how focused or broad you want the context to be.
- In summary, this controls the relevance threshold for the documents by limiting the maximum distance/dissimilarity from your question.
- Libraries (formally Groups and Tags)
- The real estate library contains many documents organized into different categories.
- By default, all documents are searched to find answers to your question.
- But the library covers a wide range of overlapping topics across many publications.
- You may want to narrow the search to specific sets of documents.
- Libraries allow you to select document categories to search.
- When you select a Library, only those documents are included.
- If you select multiple items, it combines those categories.
- This focuses the search on more targeted sets of documents.
- It helps improve relevancy by eliminating documents that may not be applicable.
- Leaving all unchecked searches everything. Selecting just what you need makes the search more precise.
- In summary, Libraries allow you to filter the search to specific document sets to get more accurate answers.
- Email Address
- If you are an "anonymous" user, you will need to enter your email address. You will be sent a link that you must click to verify the address. Please check your email spam folder for the verification email.
- If you are an "authenticated" (logged in subscriber) user, your email address is already validated and automatically inserted.
- Submit
- Click here to submit your request.
- Keyword Search
- This allows you to do a traditional keyword-based search of the document library.
- It will match and return all documents containing the words or phrases you enter.
- The search ignores any selected Groups or Tags and looks across all documents.
- A keyword search can be useful in certain situations:
- If the AI does not return an answer despite relevant context documents. This helps surface documents the AI may have missed.
- When references to your question are scattered across many documents. Keyword search casts a wider net to find them.
- If you want to triangulate facts by finding multiple mentions across documents.
- The downside is keyword search loses context and may return irrelevant documents that happen to match the words.
- In summary, keyword search complements the AI by allowing precise term matching across all documents when needed. But results may lack broader relevance.
- Note that the results are not limited to the Groups and Tags you may have optionally ticked above.
The Query Response
- Question
- The question you submitted.
- Concept
- The core concept submitted to the vector store to retrieve the context documents.
- Citations - Context Documents
- Important!
- These are the relevant context documents returned by the vector store. The concept was analyzed and submitted and the vector store returned these documents as the best matches to that concept.
- Each of these citations will be a clickable link to the actual Real Estate Books AI publication. Do not hesitate to click on these links to verify the answer you receive is correct.
- Note the number in parenthesis () next to each citation title. This is the cosine similarity distance between the submitted concept and the retrieved document. The lower the number, the higher the relevancy of the document to your concept / question.
- Important!
- Answer
- The AI analyzes your question and the submitted documents, and attempts to answer your question based on the text in the submitted documents.
- If all goes well, it's a good answer. It is also possible that given the question and the submitted documents, the AI is unable to answer your question. If this happens, the Short Answer is to re-phrase your question until the AI does give you a reasonable response.
- Total Tokens
- Total tokens used in the completion of this response. This would include the question, the response, and the development of the "concept".
- We will discuss tokens in more detailed documentation, but suffice it to say that the more tokens you use on each query, the less queries in total you are able to make on a daily or monthly basis. And, of course, the opposite is true: The less tokens you use, the more queries you will be able to make.
Follow-Up Responses
The beauty of semantic/conversational search is that the context of your discussion is maintained, so that the next question you ask in a conversation with the AI is understood to be within the scope of that conversation. Much like in human interaction.
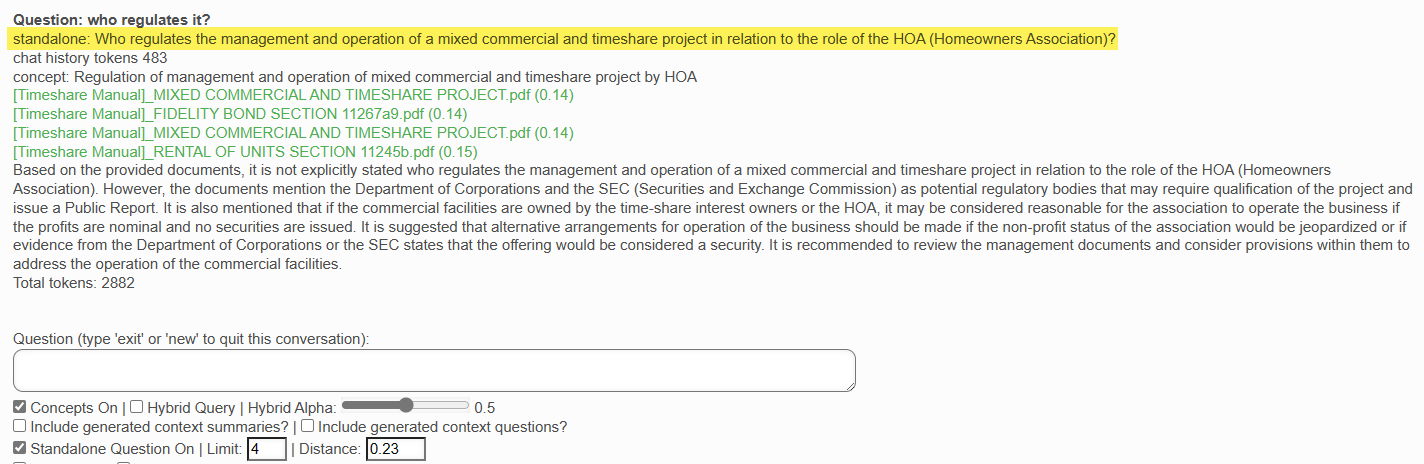
Note that the follow up question simply refers to "it". This is understood, in the context of the conversation, to mean the HOA.
Also note that the AI can't quite answer the question. This is because at the time this demonstration was executed, the Real Estate Law (regulatory/legal references) documents had not yet been added to the Real Estate Books AI library. So, the AI attempts to answer the question as best it can using what information it can find in the citations / context documents submitted -- which are part of the rest of the CA Department of Real Estate publications list (excluding the law).
Note that there are two new items included in the AI response:
- Standalone Question
- This is exactly what it says: A standalone question that can be submitted to the AI to help it remember the conversation.
- This also becomes the actual question that is submitted to the AI along with the context documents and chat history, instead of the actual question entered which, with no other context, would not be understood.
- Chat History Tokens
- The other method used to maintain the conversation context is to submit, with each question, the history of the conversation to the AI. These are the tokens accumulated in each AI call by the chat history.
Each time you want to ask a follow up question in the same conversation, this is how you do it. When you want to start a new conversation on a different subject, then enter "new" or "exit" in the Question box.
Do NOT switch subjects without doing this, or it will confuse the AI and you will get very unsatisfactory results.
Otherwise, Happy Searching!